Intelligente Betriebsüberwachung (Smart Condition Monitoring) mit Hilfe des maschinellen Lernens

Dr. Patrick Bangert
algorithmica technologies GmbH
Die üblichen Betriebsüberwachungen analysieren gewöhnlich jede Sensormessung separat, indem sie fest vorgegebene Begrenzungsinformationen auswerten. Daraus ergeben sich entweder falsche Warnmeldungen bei guten Zuständen oder es wird, umgekehrt, bei schädlichen Zuständen oft kein Alarm ausgelöst. Anders die intelligente Betriebsüberwachung (engl. Smart Condition Monitoring): Mit Hilfe von Techniken des maschinellen Lernens kann man die riesigen Datenmengen einer großen Maschine bzw. einer ganzen Werksanlage als eine kohärente Einheit analysieren und Schlussfolgerungen hinsichtlich ihres jeweiligen Gesamtzustandes ziehen. Zuerst wird aus den jeweils bereits vorhandenen relevanten Messungen ein mathematisches Modell erstellt, das die Maschine bzw. Anlage als eine gut funktionierende Einheit darstellt. Dann kann dieses optimal funktionierende Modell (bzw. dieser optimale Wert) mit dem jeweils aktuellen Zustandswert verglichen werden. Stimmen beide überein, befindet sich die Maschine (respektive die Anlage) in einem wünschenswerten, optimalen Gesamtzustand. Stimmen die beiden Werte nicht überein, wird ein Alarm ausgelöst, so dass eine Wartung zu erfolgen hat. Diese Methode ist weitaus erfolgreicher als die übliche Betriebsüberwachung. Die intelligente Überwachung verhindert falschen Alarm und Warnmeldungen werden nur bei wirklich schadhaften Zuständen herausgegeben.
Jede Maschine wird irgendwann einmal den Punkt eines schadhaften Zustandes erreichen. Dieser Punkt bedeutet noch nicht den kompletten Shutdown oder Zusammenbruch der Maschine, aber es ist ein Punkt, an dem offenbar wird, dass die Maschine sich nicht mehr so verhält, wie sie sollte, so dass eine Wartung notwendig wird, um sie wieder in den Zustand ihrer optimalen Funktionsfähigkeit zu versetzen. Ob es sich bei dieser Maschine um eine rotierende Maschine (Pumpe, Kompressor, Gas- oder Dampfturbine usw.) oder um eine nicht rotierende Maschine handelt (Wärmetauscher, Destillationstürme, Ventile usw.), stets fragen wir: Befindet sich die Maschine derzeit in einem optimalen Zustand? Das ist das Aufgabenfeld unserer „Intelligenten Betriebsüberwachung“ (engl. Smart Condition Monitoring).
Bei der gebräuchlichsten Art der Betriebsüberwachung schaut man sich jede Sensor-Messung einer Maschine an und bestimmt einen Ober- und Unterwert als jeweilige Begrenzungen. Bewegt sich der derzeitige Wert innerhalb dieser Grenzen, gilt die Maschine als gesund. Gerät der derzeitige Wert unterhalb oder oberhalb dieser Begrenzungen, gilt die Maschine als suboptimal, so dass ein Warnsignal ausgesendet wird.
Bei dieser Vorgehensweise ist bekannt, dass oft ein falscher Alarm ausgelöst wird, d.h. es wird eine Warnmeldung auch für solche Zustände ausgesendet, die eigentlich noch einen gesunden Gesamtzustand der Maschine darstellen. Darüber hinaus gibt es das Problem der fehlenden Alarmmeldungen, wenn es problematische Situationen gibt, die aber keine Warnmeldung auslösen. Beim ersten Problem vergeudet man Zeit und Ressourcen und entzieht die Maschine ihrer Verfügbarkeit. Das zweite Problem ist noch gefährlicher, denn es kann zu schwerwiegendem Schäden führen – mit damit verbundenen Kollateralschäden, Reparaturkosten und Produktionverlusten.
Beide Probleme ergeben sich durch die gleiche Ursache: Den optimalen Gesundheitszustand einer komplexen Maschine kann man nicht zuverlässig an den Analysen von Einzelmessungen ablesen. Vielmehr müssen wir die Kombination verschiedenster Messungen berücksichtigen, um zu einer tatsächlichen Zustandsbeschreibung zu kommen.
Wir können die Messungen sinnvoll strukturieren, indem wir ein mathematisches Modell erstellen, bei dem die einzelne Messung in Beziehung zu allen anderen Messungen gesetzt wird.
Nehmen wir beispielsweise die Exit-Druck eines Kompressors. Dieser Wert wird beeinflusst von der Temperatur des Mediums, der Rotationsrate der Maschine, der Komposition des Mediums sowie von einigen anderen Parametern. In Kenntnis dieser Parameter können wir berechnen, wie hoch der Exit-Druck sein sollte. Um ihn zu berechnen, müssen wir die Beziehung zwischen all diesen Parametern in eine mathematische Form (= Gleichung) gießen.
Wollten wir diese Gleichung mit Hilfe von Expertenwissen erstellen, wäre dies viel zu zeitaufwändig, um praktikabel zu sein, denn diese Gleichung wäre für jeden Hersteller und jedes Modell einer Maschine und für jede Art von Zustand, in der sich die Maschine befinden könnte, sehr unterschiedlich. Aus ganz praktischen Gründen ist ein solches Modell darum nur machbar, wenn es schnell und ohne menschlichen Aufwand erstellt werden kann.
Das ist das Spezialfeld des maschinellen Lernens. Solche Methoden basieren auf den gemessenen Daten zu einer Zeit, da die Maschine sich in einem optimalen Zustand befand. Aufgrund dieser (historischen) Daten erstellen die Methoden des maschinellen Lernens automatisch und ohne menschlichen Aufwand eine mathematische Repräsentation (=Modell) des Beziehungsgeflechts aller einschlägigen Parameter der Maschine. Es wird eine Art neuronales Netz erstellt.
Es kann mathematisch bewiesen werden, dass ein neuronales Netz in der Lage ist, einen komplexen Datensatz mit großer Genauigkeit darzustellen, sofern dieses Netz groß genug ist und die Daten bestimmten Gesetzen gehorchen [1,2]. Weil eine Maschine den Naturgesetzen gehorcht, ist diese Annahme unzweifelhaft richtig. Darum verwenden wir ein neuronales Netz als Grundlage, um jede Messung der Maschine in ihren Bezügen zu anderen Messungen zu modellieren. Der Algorithmus des maschinellen Lernens findet die Werte für alle Modell-Parameter, so dass das neuronale Netz die Daten sehr genau wiederspiegelt.
Auch die Entscheidung, welche Messungen einbezogen werden sollen, um eine bestimmte Messung zu modellieren, kann automatisch erfolgen. Wir verwenden dazu eine Kombination von Korrelations-Modellierungen und der sog. „principal component analysis“ [1].
Das Ergebnis ist, dass jeder Messung an der Maschine eine Formel zugeordnet wird, die in der Lage ist, den erwarteten Wert dieser Messung zu berechnen. Weil die Formel auf Daten basiert, als die Maschine völlig reibungslos lief, definiert diese Formel den optimalen Gesundheitszustand der Maschine. Abweichungen von diesen optimalen Werten werden dann als schadhafte Zustände interpretiert. Vgl. Abb. 1 als Beispiel.

Abb. 1: Die Verschiebung der zentralen Achse eines Kompressors wird gemessen (rot) und modelliert (grün), und zwar mit einer gewissen Bandbreite des Modells (hellgrün). Das Modell stellt das Verhalten der Maschine auch während der Ladungsveränderungen korrekt dar, sowohl bei hoher wie auch bei niedriger Ladung. Bei der Abbildung können wir Abweichungen zwischen Modell und Messung bei voller Ladung erkennen. Dies ist ein Indikator für ein Maschinenproblem, das einen Alarm auslösen wird.
Es ist wichtig, den optimalen Gesundheitszustand zu modellieren und dann nach Abweichungen von diesem Ausschau zu halten, weil diese „optimale Gesundheit“ den normalen Betriebszustand darstellt, zumal gerade für diesen optimalen Zustand viele Messdaten vorhanden sind. Nur wenige Daten stehen indes für Fehlverhalten einer Maschine zur Verfügung, zumal schadhafte Zustände ja ganz unterschiedliche Ursachen haben. Modelle, die auf Fehlverhalten basieren, wären darum sehr vielfältig und von Hersteller und Modell einer Maschine abhängig, so dass eine umfassende Charakterisierung von möglichen schadhaften Zuständen sehr komplex wäre. Schadhafte Zustände zu modellieren ist aber nicht nur wegen der komplexen Datenanalyse ein Problem, sondern vor allem auch aufgrund mangelnder Daten. Es handelt sich hier also um ein fundamentales Problem, das in der Praxis nicht umfassend gelöst werden kann.
Wir können jederzeit den zu erwartenden „gesunden“ Wert mit dem aktuellen Sensorwert vergleichen. Weil der erwartete Wert vom Modell errechnet wird, kennen wir auch die Wahrscheinlichkeitsverteilung der Abweichungen, d.h. wir wissen, wie oft und um welchen Wert die aktuellen Messungen vom erwarteten Wert abweichen können. Vgl. dazu Abb. 2. Aufgrund der Wahrscheinlichkeitsverteilung können wir die Wahrscheinlichkeit eines gesunden Zustands berechnen bzw. wir können – umgekehrt – aufgrund des Konfidenzintervals bestimmen, ob ein Sensor-Wert zu sehr vom gesunden Wert abweicht. Tut er das, wird ein Alarm ausgelöst.

Abb. 2: Die Abweichung zwischen dem Modellwert und dem Sensorwert (horizontale Achse) wird hier der Wahrscheinlichkeit gegenüber gestellt, mit der diese Abweichung auftritt (senkrechte Achse). Für ein gutes Modell erwarten wir eine Kurve in Glockenform, und das heißt: viele Punkte mit geringer Abweichung und wenige Punkt mit erheblicher Abweichung, wobei es insgesamt eine Symmetrie zwischen Abweichung oberhalb und Abweichungen unterhalb des Modells geben wird. Aus dieser Verteilung können wir leicht ablesen, wie wahrscheinlich eine beobachtete Abweichung ist und wie gesund der Gesamtzustand (noch) ist. Das Diagramm übersetzt somit eine sensorische Messung in einen Gesundheitsindex.
Der ausgelöste Alarm kann dann noch mit der Information darüber angereichert werden, wie schadhaft der angezeigte Zustand ist, indem er die Wahrscheinlichkeit eines schädlichen Gesundheitszustandes anzeigt. Da der erwartete Wert von einer (gewöhnlich kleinen) Zahl von Parametern der Maschine berechnet wurde, ist es im Allgemeinen möglich, die Ursache bei einer anderen Messung zu suchen. Damit wird dem menschlichen Ingenieur, dem der Alarmzustand gemeldet wurde, bei seinem Bemühen geholfen, eine Diagnose zu stellen und eine Gegenmaßnahme zu treffen.
Bei einer herkömmlichen Zustandsüberwachung zeigt sich in der Praxis häufig, dass, wenn eine Maschine von einem stabilen Zustand in einen anderen (stabilen Zustand) wechselt, viele (falsche) Alarme ausgelöst werden, weil die einfache Analyse nicht Schritt halten kann mit sich schnell verändernden Bedingungen. Weil ein neuronales Netz aber ohne Weiteres nicht-lineare Beziehungen abzubilden vermag, kann etwa auch das Hochfahren einer Maschine oder ihr Ladevorgang korrekt modelliert werden, solange alles so läuft, wie es laufen soll.
Dieser Ansatz ist ausgiebig getestet worden: für rotierende Maschinerien wie Kompressoren, Pumpen, Gas- und Dampfturbingen von mehreren Herstellern im operationalen Kontext der Energiewirtschaft, der chemischen Industrie, der Ölraffinerien und Ölförderung. Vor allem die Firma MAN Diesel and Turbo setzt diese Methode ein, um die eigenen Kompressoren und Gasturbinen in Alarmzustand zu versetzen – noch bevor der menschliche Ingenieur sich die Daten anschaut.
Unsere Partner haben bei der praktischen Umsetzung beobachten können, dass der von menschlichen Ingenieuren zu veranschlagende Aufwand zur Instandsetzung und Wartung einer Zustandsüberwachung um über 50% reduziert werden konnte, und zwar aufgrund der automatisierten Assistenz des maschinellen Lernens. Das hat vor allem damit zu tun, dass es nicht länger nötig ist, die Unter- und Obergrenzen für jede einzelne Messung mit größter Sorgfalt per Hand einzustellen, weil diese Modelle nunmehr automatisch generiert werden.
Die Fälle, in denen falscher Alarm gegeben wird („false positives“) bzw. kein Alarm gegeben wird (wenn ein solcher ausgelöst werden müsste = „false negatives“), konnten um über 90% reduziert werden. Damit konnte der Ingenieurs-Aufwand zur Diagnose von Maschinenversagen um über 60% reduziert werden, mit der Folge, dass die Wartungsbudgets sanken und die Verfügbarkeit der Maschinen um etwa 10 % erhöht werden konnte.
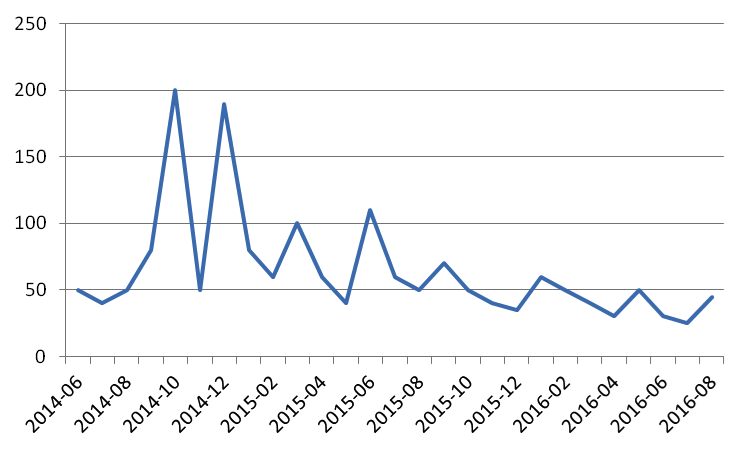
Abb. 3: Das Beispiel eines Wartungsbudgets über einen mittleren Zeitraum (2014-2016) in 1000 US$. Das Budget reduzierte sich, weil die Wartung weniger reaktiv und eher proaktiv wurde.
Wenn das Unternehmen die neuen Methoden einsetzt, wird die Wartung weniger reaktiv und eher proaktiv. Damit kann auf verschiedene Weise Geld gespart werden. Weil wir jetzt Probleme feststellen können, ehe es zu einer ungeplanten Inspektion der Anlage kommt, kann man Kollateralschäden vermeiden. Der potenzielle Produktionsverlust wird auf diese Weise reduziert. Die Kosten, um kurzfristig Personal oder Ersatzmaterial anzufordern, werden vermieden. Einen konkret auftretenden Schaden muss man freilich immer noch beheben, aber jetzt kann man dies in geplanter und präventiver Weise tun, während man es zuvor in einer Art Feuerwehr-Modus tun musste. Dadurch kann das Wartungsbudget um bis zu 50% reduziert werden.
Die zwei wichtigsten Probleme des konventionellen Ansatzes der Zustandsüberwachung, nämlich falscher Alarm bei gutem Zustand und Nicht-Alarm bei schadhaftem Zustand, konnten behoben werden. Das ist erreicht worden, indem jede Messung mit Hilfe der anderen Messungen dargestellt wird und somit alle Messungen rund um eine Maschine einbezogen werden. Diese Modelle können mit Hilfe des maschinellen Lernens automatisch generiert werden, ganz ohne menschlichen Aufwand. Die Genauigkeit dieser Modelle, mit der sie einen gesunden Zustand von einem ungesunden, schadhaften Zustand zu unterscheiden in der Lage sind, wird erheblich erhöht und führt zu einer Reduktion der falschen bzw. fehlenden Warnmeldung um über 90%.


 mit Hilfe des maschinellen Lernens")




